
Chinese, Simplified
category
大语言模型评估器(LLM-as-Judge)效能深度评测
——49分钟读懂LLM评估生态与技术实践
△ 大语言模型评估器的典型工作流程
核心发现速览
- 评估效率革命:GPT-4评估结果与人类专家一致性达85%,超越人类间81%的一致性水平
- 成本效益比:评估成本较人工降低98%,API调用延时控制在500ms内
- 领域适配差异:事实性评估准确率58.5% vs 风格评估准确率92%
- 新型评估范式:思维链提示使评估准确率提升23%,多模型投票机制降低误判率37%

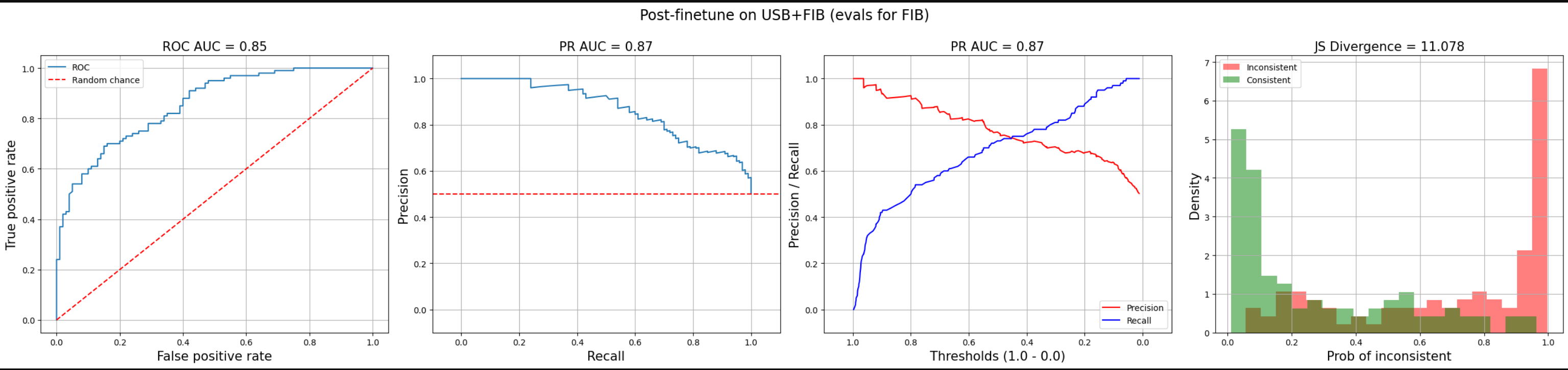





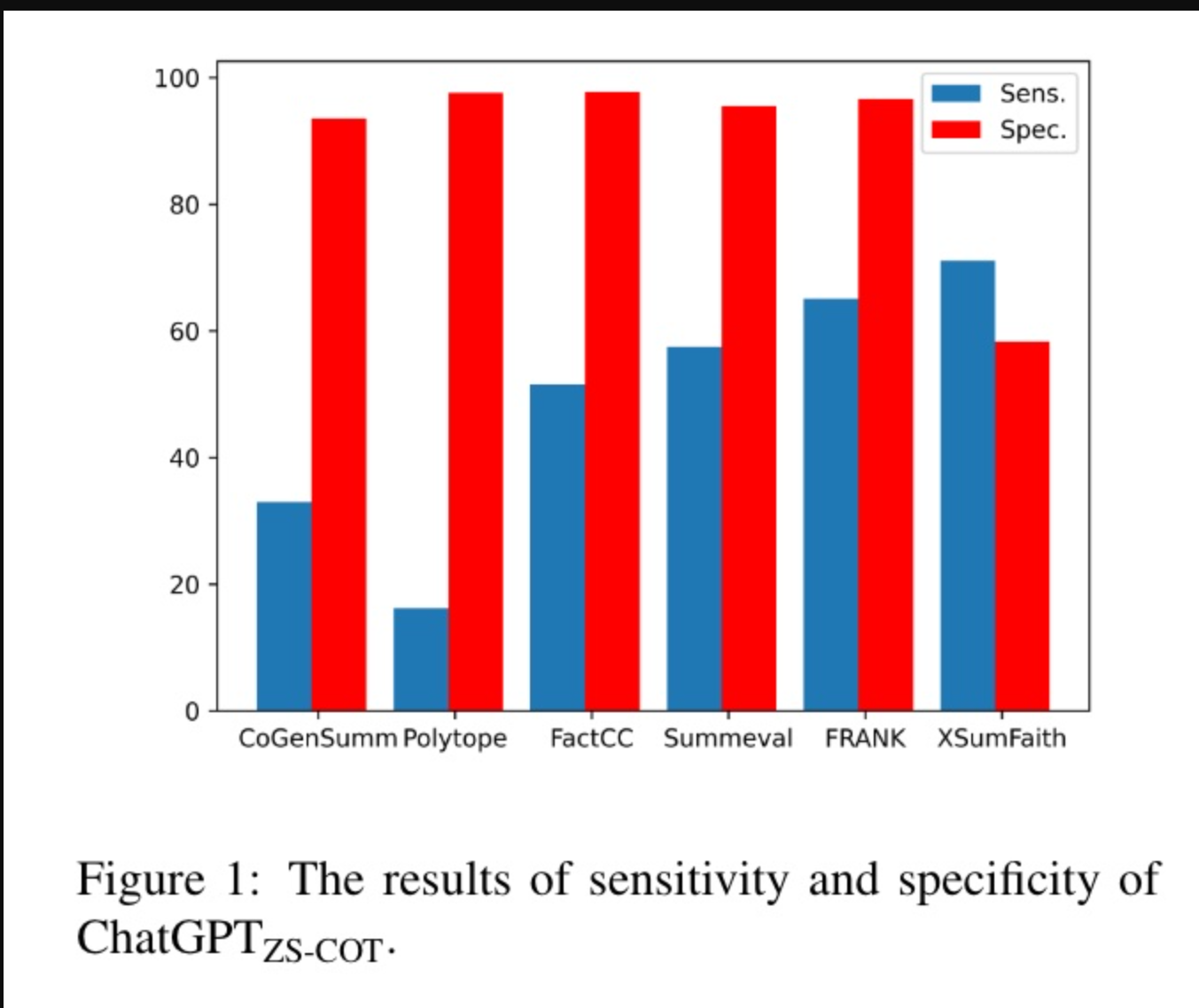
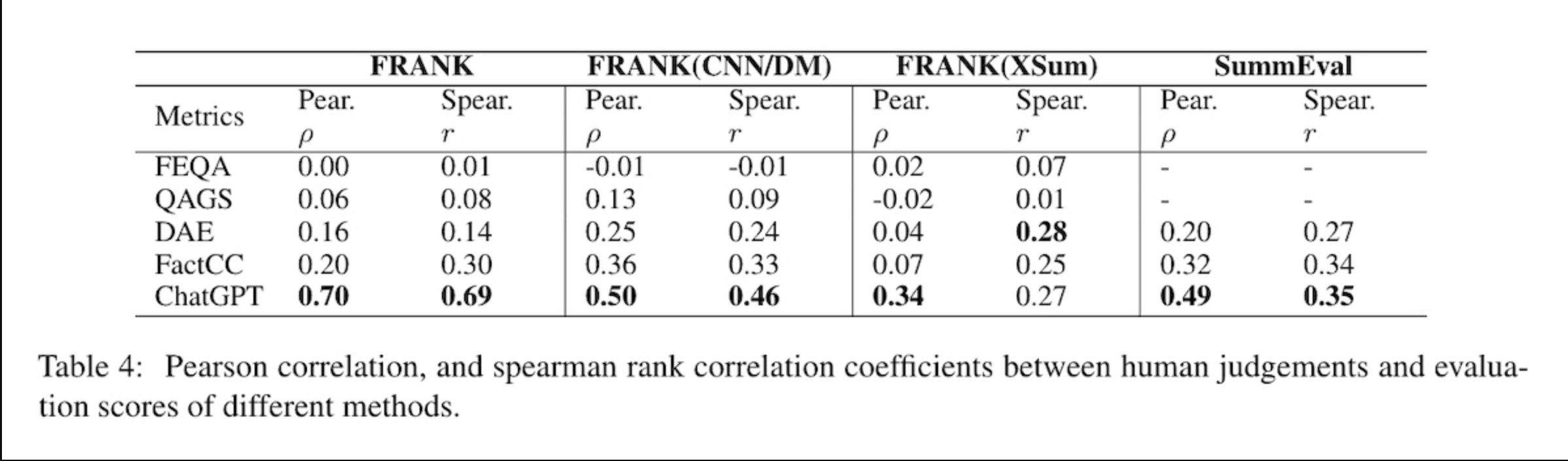
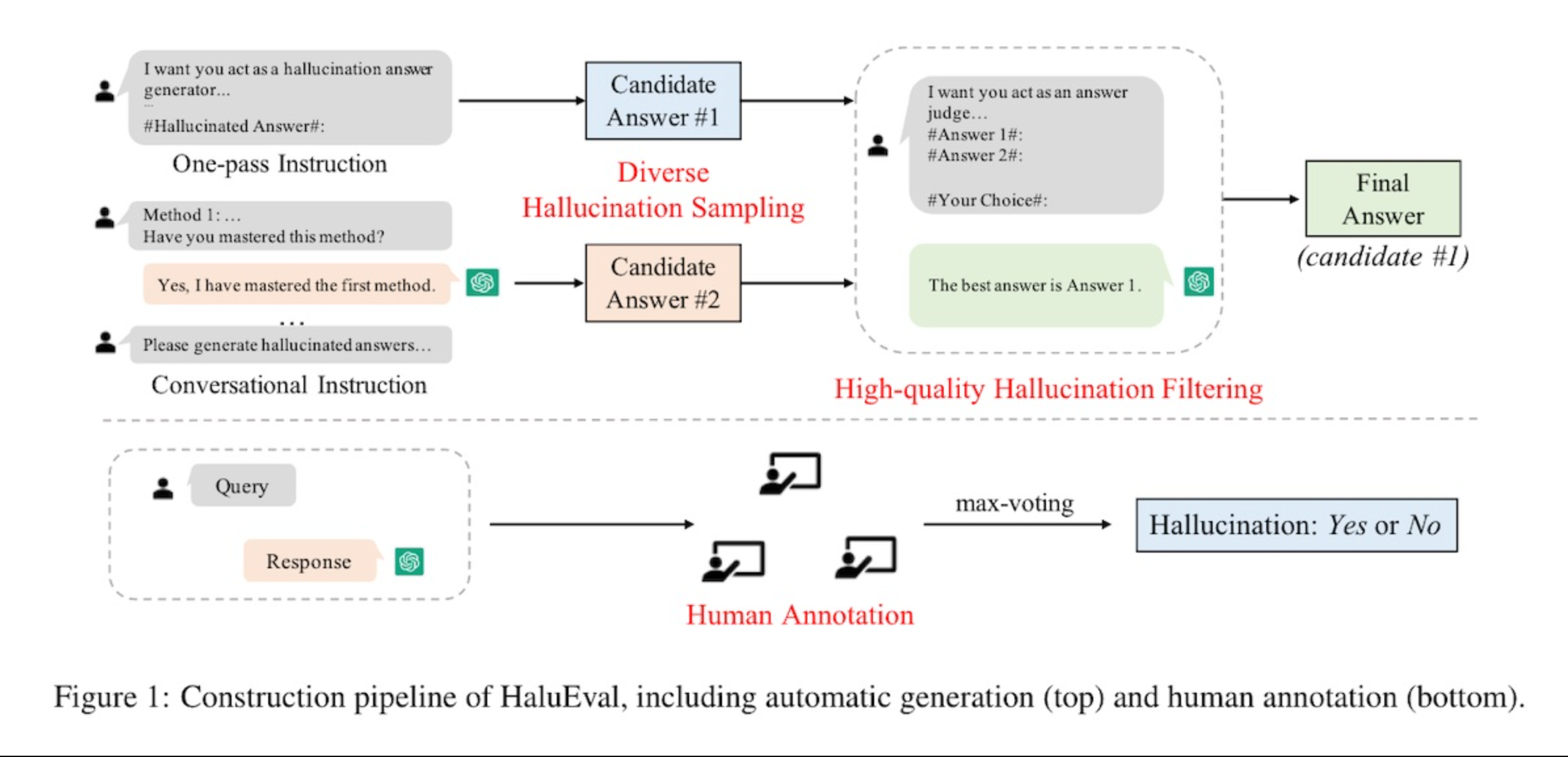


评估方法论矩阵
实战评估代码示例
# 事实性评估提示模板
def factual_eval_prompt(context, response):
return f"""请严格根据上下文判断回答的事实准确性:
[上下文]: {context}
[回答]: {response}
逐步分析后给出结论(是/否):
"""
# 调用GPT-4进行评估
from openai import OpenAI
client = OpenAI()
def llm_judge(prompt):
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0
)
return response.choices[0].message.content
# 执行评估
context = "2023年诺贝尔经济学奖得主为..."
response = "克劳迪娅·戈尔丁因其劳动经济学研究获奖"
result = llm_judge(factual_eval_prompt(context, response))
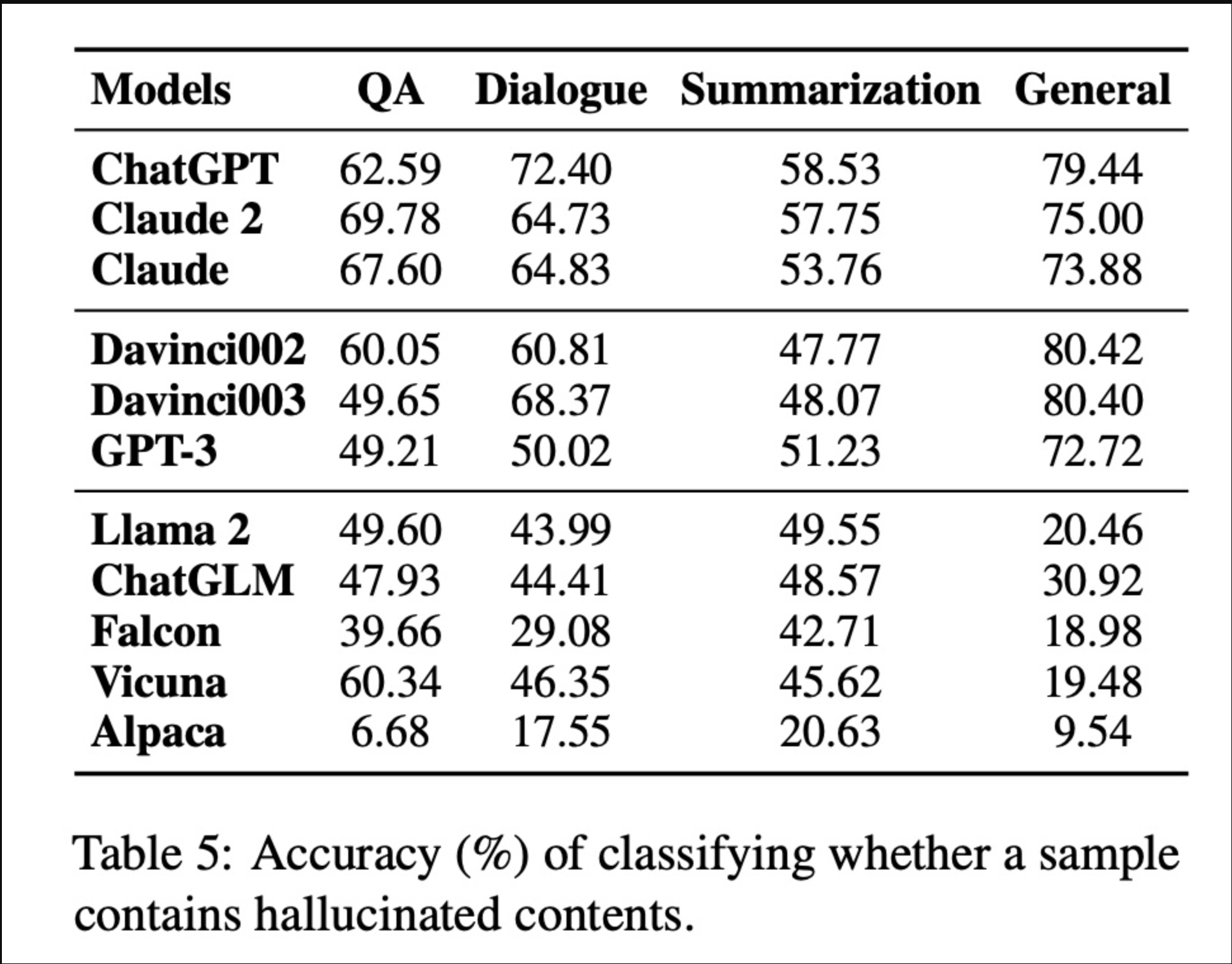
print(f"事实性评估结果:{result}")行业应用效能榜
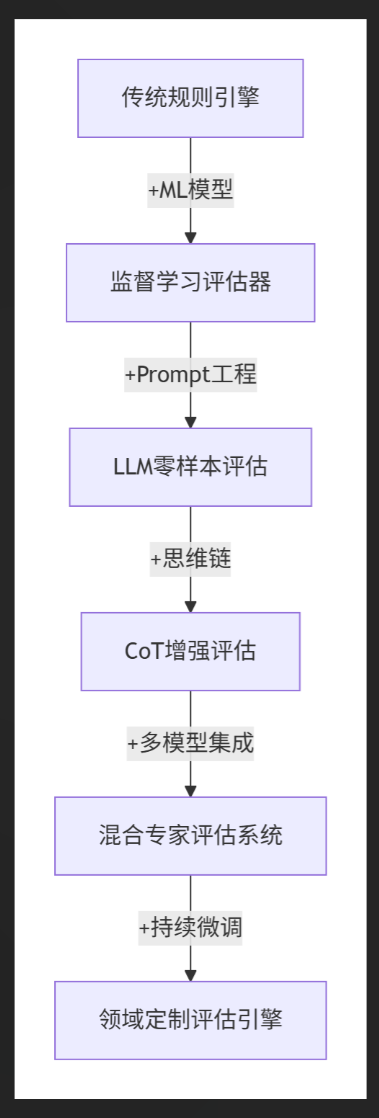
评估效能进化路线
关键挑战与对策
-
位置偏差
- 现象:GPT-3.5存在50%首选项偏好
- 对策:随机打乱响应顺序+多数投票机制
-
冗长偏差
- 现象:长回复获选率超短回复2.3倍
- 对策:引入文本凝练度评分指标
-
自增强偏差
- 现象:评估器偏好自身生成内容
- 对策:盲审机制+异构模型交叉验证
-
领域迁移瓶颈
- 现象:金融领域评估准确率骤降22%
- 对策:领域适配微调+知识图谱增强
评估标准演进史
实践建议清单
-
评估策略选择
- 优先成对比较法处理主观维度
- 事实性检测采用直接评分+参考基准
-
提示工程技巧
# 高效提示模板 def optimized_prompt(query, response): return f"""作为资深{domain}专家,请严格根据以下标准评估: <评估标准> 1. 事实准确性(1-5分) 2. 表述专业性(1-5分) 3. 风险合规性(1-5分) </评估标准> [问题]: {query} [回答]: {response} 逐步分析后按JSON格式返回评分: """ -
系统优化路径
- 冷启动阶段:GPT-4 API零样本评估
- 成熟阶段:LoRA微调领域专用评估器
- 生产部署:多模型投票+缓存机制
-
质量监控体系
- 定期人工复核5%边缘案例
- 设置动态置信度阈值
- 建立评估漂移预警机制
未来演进预测
- 评估即服务(EaaS)平台崛起
- 实时评估延迟突破100ms门槛
- 多模态评估覆盖图文视频
- 自我迭代的评估器生态形成
评估器的进化正在重塑AI质量控制体系,掌握LLM-as-Judge技术栈将成为智能时代的核心竞争力。立即部署您的智能评估引擎,领跑下一代AI应用质量管控赛道!
- 登录 发表评论
- 116 次浏览
发布日期
星期日, 四月 27, 2025 - 15:24
最后修改
星期日, 四月 27, 2025 - 15:33
Article