
category
开发能够处理现实世界任务的生成性人工智能智能体是复杂的,构建生产级智能体应用程序需要将智能体与用户界面、评估框架和持续改进机制等其他工具集成在一起。开发人员经常发现自己正在努力应对不可预测的行为、复杂的工作流程和复杂的交互网络。智能体的实验阶段特别具有挑战性,通常乏味且容易出错。如果没有强大的跟踪机制,开发人员将面临艰巨的任务,例如识别瓶颈、理解智能体推理、确保跨多个工具的无缝协调以及优化性能。这些挑战使创建有效和可靠的人工智能智能体成为一项艰巨的任务,需要创新的解决方案来简化开发并提高整体系统的可靠性。
在此背景下,Amazon SageMaker AI with MLflow提供了一个强大的解决方案,可以简化生成式AI智能体实验。在这篇文章中,我使用LangChain流行的开源LangGraph智能体框架来构建一个智能体,并展示如何对LangGraph生成的AI智能体进行详细的跟踪和评估。本文探讨了Amazon SageMaker AI with MLflow如何帮助您作为开发人员和机器学习(ML)从业者高效地进行实验,评估生成AI智能体的性能,并优化其应用程序以实现生产就绪。我还将向您展示如何使用检索增强生成评估(RAGAS)引入高级评估指标,以说明如何像RAGAS一样通过工作流定制来跟踪自定义和第三方指标。
生成式人工智能智能体开发中对高级跟踪和评估的需求
实验的一个关键功能是能够观察、记录和分析智能体在处理请求时的内部执行路径。这对于查明错误、评估决策过程和提高整体系统可靠性至关重要。跟踪工作流不仅有助于调试,还可以确保智能体在不同场景中一致执行。
生成性人工智能智能体执行的任务具有开放性,如文本生成、摘要或问答,这进一步增加了复杂性。与传统的软件测试不同,评估生成性人工智慧智能体需要超越基本准确性或延迟度量的新指标和方法。您必须评估多个维度,如正确性、毒性、相关性、连贯性、工具调用和基础性,同时跟踪执行路径以识别错误或瓶颈。
为什么SageMaker AI有MLF?
Amazon SageMaker AI提供了流行的开源MLflow的完全托管版本,为机器学习实验和生成式AI管理提供了一个强大的平台。这种组合对于使用生成型AI智能体特别强大。SageMaker AI with MLflow基于MLflow的开源传统,是一种广泛用于管理机器学习工作流程的工具,包括实验跟踪、模型注册、部署以及与可视化的指标比较。
- 可扩展性:SageMaker AI允许您轻松扩展生成性AI智能体实验,同时运行多个迭代。
- 集成跟踪:MLF集成实现了对实验跟踪、版本控制和智能体工作流的高效管理。
- 可视化:利用内置的流体流动功能监控和可视化每次实验运行的性能。
- 机器学习团队的连续性:已经使用MLflow进行经典机器学习的组织可以采用智能体,而无需重新检查其MLOps堆栈,从而减少了生成人工智能采用的摩擦。
- AWS生态系统优势:除了MLflow之外,SageMaker AI还为生成式AI开发提供了一个全面的生态系统,包括访问基础模型、许多托管服务、简化的基础设施和集成安全。
这一演变将SageMaker AI与MLflow定位为传统ML和尖端生成AI智能体开发的统一平台。
SageMaker AI的关键特性
SageMaker AI的MLflow功能直接解决了智能体实验的核心挑战——跟踪智能体行为、评估智能体性能和统一治理。
- 实验跟踪:比较LangGraph智能体的不同运行,并跟踪迭代过程中性能的变化。
- 智能体版本控制:在整个开发生命周期中跟踪智能体的不同版本,以迭代地改进和改进智能体。
- 统一的智能体治理:在SageMaker AI中注册的智能体会自动出现在SageMakerAI的MLflow控制台中,从而实现跨团队的管理、评估和治理的协作方法。
- 可扩展的基础设施:使用SageMaker AI的托管基础设施运行大规模实验,而无需担心资源管理。
LangGraph generative AI agents
LangGraph offers a powerful and flexible approach to designing generative AI agents tailored to your company’s specific needs. LangGraph’s controllable agent framework is engineered for production use, providing low-level customization options to craft bespoke solutions.
In this post, I show you how to create a simple finance assistant agent equipped with a tool to retrieve financial data from a datastore, as depicted in the following diagram. This post’s sample agent, along with all necessary code, is available on the GitHub repository, ready for you to replicate and adapt it for your own applications.

Solution code
You can follow and execute the full example code from the aws-samples GitHub repository. I use snippets from the code in the repository to illustrate evaluation and tracking approaches in the reminder of this post.
Prerequisites
- An AWS account with billing enabled.
- A SageMakerAI domain. For more information, see Use quick setup for Amazon SageMaker AI.
- Access to a running SageMaker AI with MLflow tracking server in Amazon SageMaker Studio. For more information, see the instructions for setting up a new MLflow tracking server.
- Access to the Amazon Bedrock foundation models for agent and evaluation tasks.
Trace generative AI agents with SageMaker AI with MLflow
MLflow’s tracing capabilities are essential for understanding the behavior of your LangGraph agent. The MLflow tracking is an API and UI for logging parameters, code versions, metrics, and output files when running your machine learning code and for later visualizing the results.
MLflow tracing is a feature that enhances observability in your generative AI agent by capturing detailed information about the execution of the agent services, nodes, and tools. Tracing provides a way to record the inputs, outputs, and metadata associated with each intermediate step of a request, enabling you to easily pinpoint the source of bugs and unexpected behaviors.
The MLfow tracking UI displays the traces exported under the MLflow Traces tab for the selected MLflow experimentation, as shown in the following image.

此外,通过选择请求ID,您可以查看智能体输入或提示调用的详细跟踪。选择请求ID将打开一个可折叠视图,其中包含从输入到最终输出的调用工作流的每个步骤捕获的结果,如下图所示。
SageMaker AI with MLflow跟踪LangGraph智能体中的所有节点,并在MLflow UI中显示跟踪,其中包含每个节点的详细输入、输出、使用令牌和具有源类型(人类、工具、AI)的多序列消息。该显示还捕获了整个智能体工作流的执行时间,提供了每个节点的时间细分。总的来说,追踪对于生成型AI至关重要,原因如下:智能体
- 性能监控:跟踪使您能够监督智能体的行为,并确保其有效运行,帮助识别故障、不准确或有偏差的输出。
- 超时管理:使用超时进行跟踪有助于防止智能体陷入长时间运行的操作或无限循环,有助于确保更好的资源管理和响应能力。
- 调试和故障排除:对于基于用户输入具有多个步骤和不同序列的复杂智能体,跟踪有助于查明执行过程中引入问题的位置。
- 可解释性:跟踪提供了对智能体决策过程的洞察,帮助您理解其行为背后的推理。例如,您可以看到工具的名称和处理类型——人类、工具或人工智能。
- 优化:捕获和传播AI系统的执行跟踪可以实现AI系统的端到端优化,包括优化提示和元数据等异构参数。
- 合规性和安全性:通过提供审计日志和实时监控功能,跟踪有助于维护监管合规性并确保运营安全。
- 成本跟踪:跟踪可以帮助分析资源使用情况(输入令牌、输出令牌)以及运行AI智能体的相关外推成本。
- 适应和学习:跟踪允许观察智能体如何与提示和数据交互,提供可用于随着时间的推移改进和调整智能体性能的见解。
在MLflowUI中,您可以选择任务名称来查看在任何智能体步骤捕获的详细信息,因为它为输入请求提示或调用提供服务,如下图所示。

By implementing proper tracing, you can gain deeper insights into your generative AI agents’ behavior, optimize their performance, and make sure that they operate reliably and securely.
Configure tracing for agent
For fine-grained control and flexibility in tracking, you can use MLflow’s tracing decorator APIs. With these APIs, you can add tracing to specific agentic nodes, functions, or code blocks with minimal modifications.
This configuration allows users to:
- Pinpoint performance bottlenecks in the LangGraph agent
- Track decision-making processes
- Monitor error rates and types
- Analyze patterns in agent behavior across different scenarios
This approach allows you to specify exactly what you want to track in your experiment. Additionally, MLflow offers out-of-the box tracing comparability with LangChain for basic tracing through MLflow’s autologging feature mlflow.langchain.autolog(). With SageMaker AI with MLflow, you can gain deep insights into the LangGraph agent’s performance and behavior, facilitating easier debugging, optimization, and monitoring, in both development and production environments.
Evaluate with MLflow
You can use MLflow’s evaluation capabilities to help assess the performance of the LangGraph large language model (LLM) agent and objectively measure its effectiveness in various scenarios. The important aspects of evaluation are:
- Evaluation metrics: MLflow offers many default metrics such as LLM-as-a-Judge, accuracy, and latency metrics that you can specify for evaluation and have the flexibility to define custom LLM-specific metrics tailored to the agent. For instance, you can introduce custom metrics for Correct Financial Advice, Adherence to Regulatory Guidelines, and Usefulness of Tool Invocations.
- Evaluation dataset: Prepare a dataset for evaluation that reflects real-world queries and scenarios. The dataset should include example questions, expected answers, and relevant context data.
- Run evaluation using MLflow evaluate library: MLflow’s
mlflow.evaluate()returns comprehensive evaluation results, which can be viewed directly in the code or through the SageMaker AI with MLflow UI for a more visual representation.
The following is a snippet for how mlflow.evaluate(), can be used to execute evaluation on agents. You can follow this example by running the code in the same aws-samples GitHub repository.
This code snippet employs MLflow’s evaluate() function to rigorously assess the performance of a LangGraph LLM agent, comparing its responses to a predefined ground truth dataset that’s maintained in the golden_questions_answer.jsonl file in the aws-samples GitHub repository. By specifying “model_type”:”question-answering”, MLflow applies relevant evaluation metrics for question-answering tasks, such as accuracy and coherence. Additionally, the extra_metrics parameter allows you to incorporate custom, domain-specific metrics tailored to the agent’s specific application, enabling a comprehensive and nuanced evaluation beyond standard benchmarks. The results of this evaluation are then logged in MLflow (as shown in the following image), providing a centralized and traceable record of the agent’s performance, facilitating iterative improvement and informed deployment decisions. The MLflow evaluation is captured as part of the MLflow execution run.
You can open the SageMaker AI with MLflow tracking server and see the list of MLflow execution runs for the specified MLflow experiment, as shown in the following image.

The evaluation metrics are captured within the MLflow execution along with model metrics and the accompanying artifacts, as shown in the following image.

Furthermore, the evaluation metrics are also displayed under the Model metrics tab within a selected MLflow execution run, as shown in the following image.

Finally, as shown in the following image, you can compare different variations and versions of the agent during the development phase by selecting the compare checkbox option in the MLflow UI between selected MLflow execution experimentation runs. This can help compare and select the best functioning agent version for deployment or with other decision making processes for agent development.

Register the LangGraph agent
You can use SageMaker AI with MLflow artifacts to register the LangGraph agent along with any other item as required or that you’ve produced. All the artifacts are stored in the SageMaker AI with MLflow tracking server’s configured Amazon Simple Storage Service (Amazon S3) bucket. Registering the LangGraph agent is crucial for governance and lifecycle management. It provides a centralized repository for tracking, versioning, and deploying the agents. Think of it as a catalog of your validated AI assets.
As shown in the following figure, you can see the artifacts captured under the Artifact tab within the MLflow execution run.

MLflow automatically captures and logs agent-related information files such as the evaluation results and the consumed libraries in the requirements.txt file. Furthermore, a successfully logged LangGraph agent as a MLflow model can be loaded and used for inference using mlflow.langchain.load_model(model_uri). Registering the generative AI agent after rigorous evaluation helps ensure that you’re promoting a proven and validated agent to production. This practice helps prevent the deployment of poorly performing or unreliable agents, helping to safeguard the user experience and the integrity of your applications. Post-evaluation registration is critical to make sure that the experiment with the best result is the one that gets promoted to production.
Use MLflow to experiment and evaluate with external libraries (such as RAGAS)
MLflow’s flexibility allows for seamless integration with external libraries, enhancing your ability to experiment and evaluate LangChain LangGraph agents. You can extend SageMaker MLflow to include external evaluation libraries such as RAGAS for comprehensive LangGraph agent assessment. This integration enables ML practitioners to use RAGAS’s specialized LLM evaluation metrics while benefiting from MLflow’s experiment tracking and visualization capabilities. By logging RAGAS metrics directly to SageMaker AI with MLflow, you can easily compare different versions of the LangGraph agent across multiple runs, gaining deeper insights into its performance.
RAGAS is an open source library that provide tools specifically for evaluation of LLM applications and generative AI agents. RAGAS includes a method ragas.evaluate(), to run evaluations for LLM agents with choice of LLM models (evaluators) for scoring the evaluation, and extensive list of default metrics. To incorporate RAGAS metrics into your MLflow experiments, you can use the following approach.
You can follow this example by running the notebook in the GitHub repository additional_evaluations_with_ragas.ipynb.
The evaluation results using RAGAS metrics from the above code are shown in the following figure.

Subsequently, the computed RAGAS evaluations metrics can be exported and tracked in the SageMaker AI with MLflow tracking server as part of the MLflow experimentation run. See the following code snippet for illustration and the full code can be found in the notebook in the same aws-samples GitHub repository.
You can view the RAGAS metrics logged by MLflow in the SageMaker AI with MLflow UI on the Model metrics tab, as shown in the following image.

从实验到生产:与SageMaker合作批准,进行流式追踪和评估
在真实的部署场景中,MLflow使用LangGraph智能体的跟踪和评估功能可以显著简化从实验到生产的过程。
想象一下,一个由数据科学家和机器学习工程师组成的大型团队在智能体平台上工作,如下图所示。通过MLflow,他们可以创建复杂的智能体,可以处理复杂的查询、处理返回并提供产品推荐。在实验阶段,团队可以使用MLflow记录智能体的不同版本,跟踪性能和评估指标,如响应准确性、延迟和其他指标。MLflow的跟踪功能允许他们分析智能体的决策过程,确定需要改进的领域。许多实验的结果都会通过MLflow自动记录到SageMaker AI中。团队可以使用MLflow UI进行协作、比较和选择性能最佳的智能体版本,并决定一个生产就绪版本,所有这些都由SageMaker AI中记录的不同数据集提供信息。
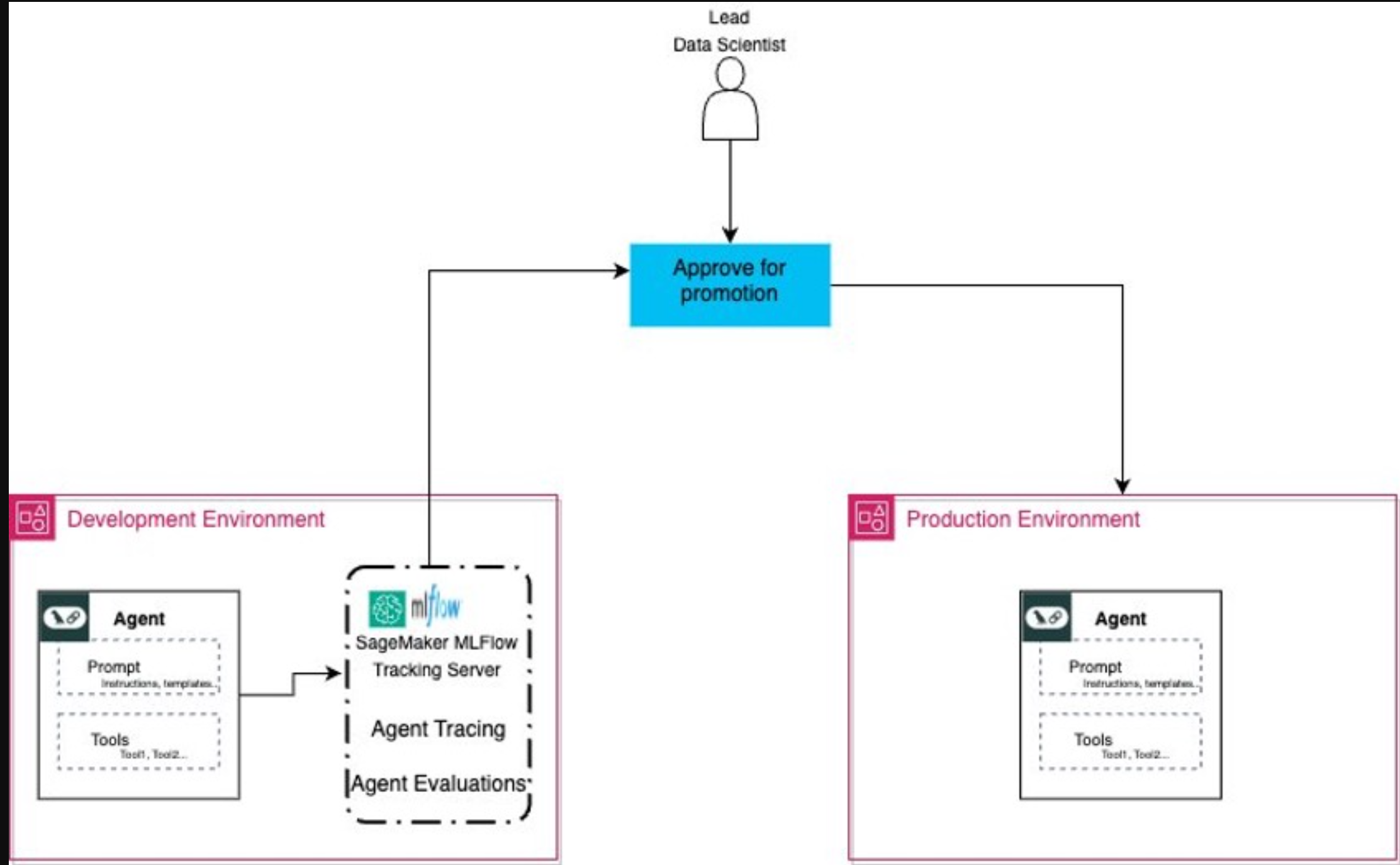
有了这些数据,团队可以向利益相关者提供一个清晰的、数据驱动的案例,以促进智能体投入生产。经理和合规官可以查看智能体的性能历史,检查特定的交互痕迹,并验证智能体是否符合所有必要的标准。获得批准后,具有MLflow注册智能体的SageMaker AI有助于顺利过渡到部署,有助于确保通过评估的智能体的确切版本是上线的版本。这种协作、可追溯的方法不仅加快了开发周期,还增强了人们对生产中生成人工智能智能体的可靠性和有效性的信心。
清理
为了避免产生不必要的费用,请使用以下步骤清理本文中使用的资源:
- 删除SageMaker AI和MLflow跟踪服务器:
- 在SageMaker Studio中,停止并删除任何正在运行的工作流跟踪服务器实例
- 撤销亚马逊基岩模型访问权限:
- 转到Amazon Bedrock控制台。
- 导航到“模型访问”,并删除为此项目启用的任何模型的访问权限。
删除SageMaker域(如果不需要):
- 打开SageMaker控制台。
- 导航到“域”部分。
- 选择为此项目创建的域。
- 选择“删除域”并确认操作。
- 同时删除所有关联的S3存储桶和IAM角色。
结论
在这篇文章中,我向您展示了如何将LangChain的LangGraph、Amazon SageMaker AI和MLflow结合起来,展示了一个强大的工作流,用于开发、评估和部署复杂的生成式AI智能体。这种集成提供了所需的工具,可以深入了解生成式AI智能体的性能,快速迭代,并在整个开发过程中保持版本控制。
随着人工智能领域的不断发展,像这样的工具对于管理生成人工智能智能体日益复杂的问题至关重要,并确保其有效性,同时考虑以下因素:,
- 可追溯性至关重要:使用SageMaker MLflow有效跟踪智能体执行路径对于调试、优化以及帮助确保复杂生成AI工作流中的一致性能至关重要。通过对智能体流程的详细记录分析,查明问题、了解决策、检查交互痕迹并提高整体系统可靠性。
- 评估推动改进:使用MLF的evaluate()函数和与RAGAS等外部库的集成,标准化和定制的评估指标提供了对智能体性能的量化洞察,指导迭代改进和明智的部署决策。
- 协作和治理至关重要:SageMaker AI通过MLflow促进的统一治理实现了从数据科学家到合规官的团队之间的无缝协作,有助于确保在生产环境中负责任和可靠地部署生成性AI智能体。
通过接受这些原则并使用本文中概述的工具,开发人员和机器学习从业者可以自信地驾驭生成式人工智能智能体开发和部署的复杂性,构建强大可靠的应用程序,提供真正的商业价值。现在,轮到您在智能体工作流程中释放高级跟踪、评估和协作的潜力了!深入aws示例GitHub存储库,开始使用LangChain的LangGraph、Amazon SageMaker AI和MLflow的强大功能来生成AI项目。
- 登录 发表评论
- 29 次浏览