
category
本指南适用于任何从事LLM驱动系统工作的人——从工程师到产品经理——寻找“LLM评估介绍”。
我们将介绍评估LLM驱动应用程序的基础知识,而不会过于技术化。只要你知道如何在你的产品中使用LLM,你就可以开始了!
我们将介绍:
- 评估LLM和LLM驱动产品之间的区别。
- LLM评估方法,从人工标记到自动评估。
- 当您需要LLM评估时,从实验到持续监测。
本指南将重点介绍核心评估原则和工作流程。
想要深入了解方法吗?探索LLM评估指标指南。
更喜欢代码示例?查看Evidently库和文档快速入门。
还是视频?这是一个youtube播放列表,其中包含LLM评估的简短介绍。
太长,读不下去了
- LLM评估(“evals”)评估模型的性能,以确保输出准确、安全,并符合用户需求。
- LLM模型评估侧重于编码、翻译和解决数学问题等原始能力,通常用标准化的基准来衡量。
- LLM产品评估使用手动和自动方法评估整个LLM动力系统执行其构建任务的能力。
- 手动LLM评估涉及领域专家或人工审阅者注释和检查输出准确性和质量。
- 自动LLM评估可以基于参考:您可以在实验、回归测试和压力测试期间将输出与已知的基本事实进行比较。
- 无参考的自动化LLM评估直接评估输出,通常用于生产监控、护栏和复杂的对话场景。
- 法学硕士的评估方法和指标各不相同,法学硕士评委是实践中最受欢迎的方法之一。
在我们谈论法学硕士评估之前,让我们先确定一下我们正在评估什么。
什么是LLM产品?

基于LLM的产品使用大型语言模型(LLM)作为其功能的一部分。
这些产品既可以包括面向用户的功能,如支持聊天机器人,也可以包括内部工具,如营销文案生成器。
您可以将LLM功能添加到现有软件中,例如允许用户使用自然语言查询数据。或者,您可以创建全新的LLM应用程序,如以LLM为核心的会话助手。
以下是一些示例:
- Vimeo构建了一个基于LLM的客户帮助台聊天机器人。
- Wayfair为数字销售代理开发了一款人工智能助手。
- Pinterest帮助数据分析师使用自然语言编写SQL查询。 、
- Yelp在评论中检测到不恰当的语言。
- OLX从非结构化广告中提取特定的工作角色。
所有这些应用程序都在LLM上运行:基于大量数据训练的现成文本模型。LLM可以通过遵循指令提示来处理各种任务:编写文本、提取信息、生成代码、翻译或进行整个对话。
有些任务,比如生成产品描述,可能只需要一个提示。然而,大多数LLM驱动的产品都变得更加复杂。例如,您可以将多个提示链接在一起,例如在文案助理中拆分内容生成和样式对齐。
一种流行的LLM驱动应用程序是RAG系统,它代表检索增强生成。尽管名字很吓人,但这是一个简单的概念:将LLM与搜索相结合。当用户提出问题时,系统会查找相关文档,并将问题和发现的上下文发送给LLM以生成答案。例如,基于RAG的支持聊天机器人可以从帮助中心数据库中提取信息,并在其回复中包含相关文章的链接。如果您正在使用RAG,我们有一个单独的RAG评估指南。
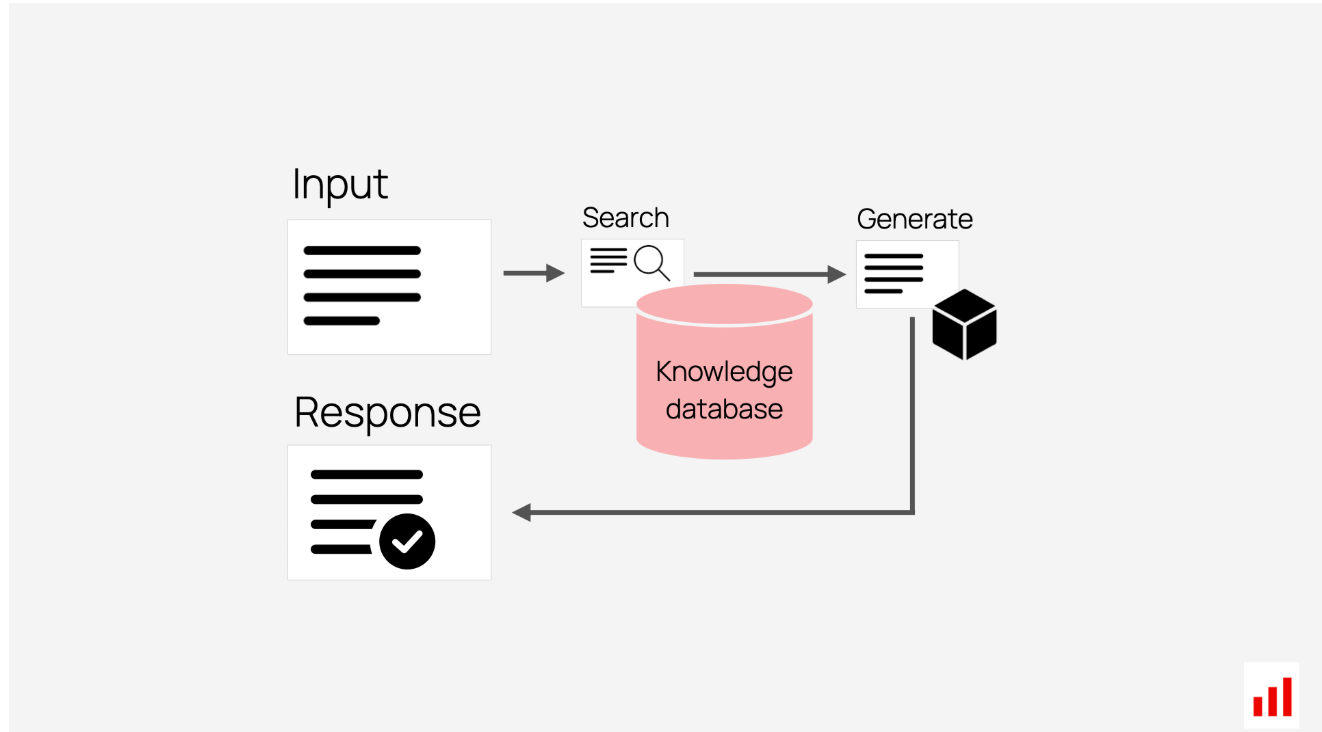
RAG系统将搜索与生成相结合。
您还可以创建基于LLM的代理,以自动化需要顺序推理的复杂工作流程:从纠正代码到计划和预订旅行。代理人不仅仅是写短信,他们还可以使用你给他们的工具。例如,查询数据库或发送日历邀请。代理系统可能会变得非常复杂,需要多步计划、数十个提示和“记忆”来跟踪进度。
想要更多的例子吗?查看这个真实世界的LLM应用程序集合。
在创建LLM驱动的系统时,你会问:它工作得怎么样?它能处理我需要的所有场景吗?我能改进它吗?
要回答这些问题,你需要LLM评估。
什么是LLM评估?

LLM评估,简称“evals”,有助于评估大型语言模型的性能,以确保输出准确、安全,并符合用户需求。
该术语适用于两种关键情况:
- LLM本身的评估。
- 评估使用LLM构建的系统。
这是一个重要的区别:虽然一些评估方法可能会重叠,但这些评估在精神上却大不相同。
LLM模型评估
当直接评估LLM时,重点是它的“原始”能力,比如编码、翻译文本或解决数学问题。研究人员为此使用标准化的LLM基准。例如,他们可以评估:
- 模型对历史事实的“了解”程度如何。
- 它能做出多好的逻辑推理。
- 它如何应对不安全或对抗性的输入。
有数百个LLM基准测试,每个都有自己的测试用例集。大多数问题都包含已知正确答案的问题,评估过程会检查模型的回答与这些答案的匹配程度。一些基准使用更复杂的方法,如众包响应排名。

100多个法学硕士评估基准。查看此收藏以获取更多示例。
LLM基准测试允许您直接比较模型。公共排行榜(比如这个)有助于跟踪每个LLM在基准测试中的表现,并回答诸如“哪个开源LLM擅长编码?”之类的问题
然而,尽管这些LLM基准对于选择模型和跟踪行业进展非常有用,但它们对于评估现实世界的产品并不是很有用。它们测试的是广泛的功能,而不是系统可能处理的特定输入。他们也只关注LLM,但你的产品将涉及其他组件。
LLM产品评估
LLM产品评估评估整个系统在其特定任务中的性能。
这不仅包括LLM,还包括其他所有内容:提示、连接它们的逻辑、用于增强答案的知识数据库等。您还可以对符合用例的数据运行这些测试,例如真实的客户支持查询。
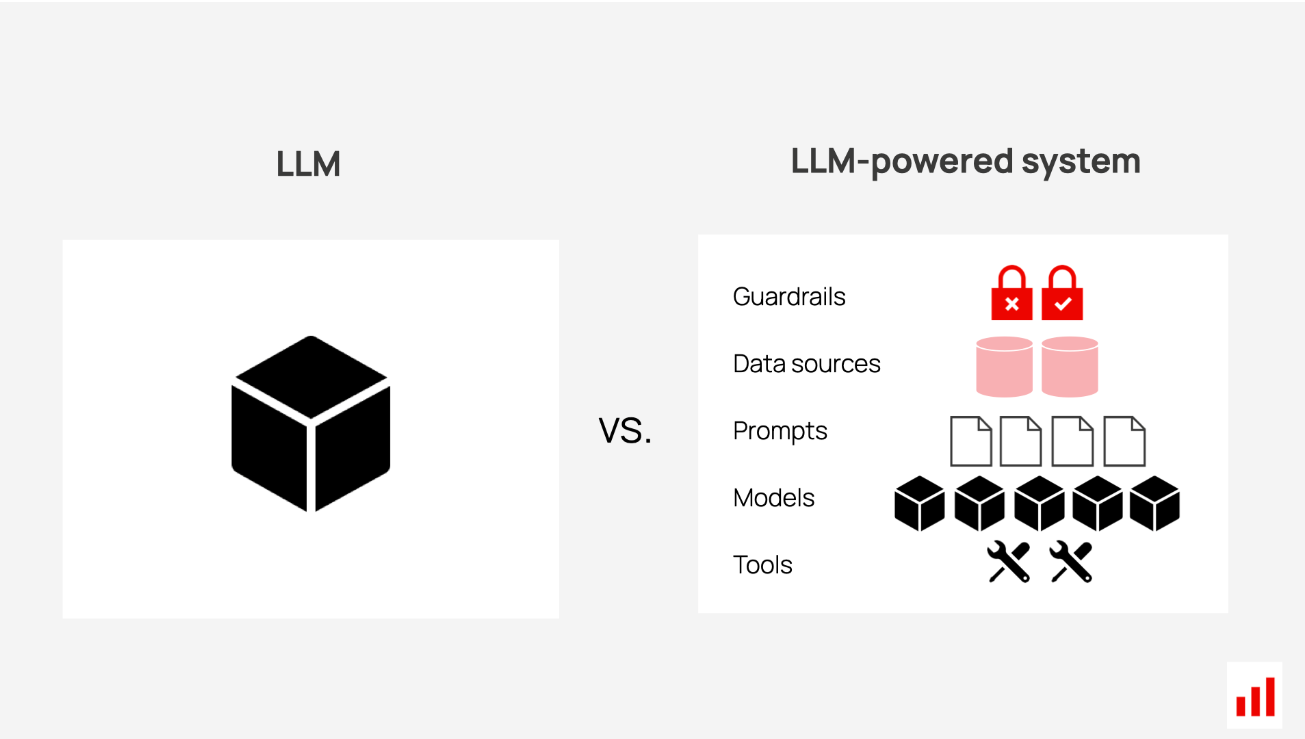
此类应用程序级评估通常涉及两个主要方面:
- 能力。LLM产品能做好它应该做的事情吗?
- 风险。其输出是否可能造成伤害?
然而,具体的质量标准会有所不同。什么定义“好”,什么定义“错”取决于用例。例如,如果你正在开发一个问答系统,你可能想评估:
- 正确。法学硕士是否提供基于事实的答案,而不编造事实?
- 乐于助人。答案是否完全回答了用户的问题?
- 文本样式。语气是否清晰、专业,是否接近现有的品牌风格?
- 格式。响应可能需要符合长度限制或始终链接到源。
在安全方面,您可能想测试您的问答系统是否不会产生有偏见或有毒的输出,或者即使被激怒也不会泄露敏感数据。

在设计LLM评估时,您需要根据应用程序的目的、风险和您观察到的错误类型来缩小标准范围。你的评估实际上应该有助于做出决定。新的提示效果更好吗?应用程序准备好上线了吗?
以“流利”或“连贯性”为标准。大多数现代法学硕士已经擅长生成自然、合乎逻辑的文本。一个完美的流利度分数可能在纸上看起来不错,但不会提供任何有用的信息。但是,如果你正在与一个能力较弱的较小的本地法学硕士合作,那么流利度测试是有意义的。
即使是积极的标准也不总是普遍适用的。在大多数情况下,事实的准确性是一件大事。但如果你构建了一个工具来为营销活动产生想法,那么编造可能就是重点。在这种情况下,你会更关心多样性和创造力,而不是幻觉。
这是LLM产品评估和基准之间的核心区别。基准测试就像学校考试一样——它们衡量的是一般技能。LLM产品评估更像是工作绩效评估。他们检查系统是否在“雇佣”的特定任务中表现出色,这取决于你使用的工作和工具。
LLM Product Evaluation |
LLM Model Evaluation |
|---|---|
| Focus | Ensuring accurate, safe outputs for a specific task. |
| Scope | Testing the LLM-powered system (with prompt chains, guardrails, integrations, etc). |
| Evaluation data | Custom, scenario-based datasets. |
| Evaluation scenario | Iterative testing from development to production. |
| Example task | Assessing a support chatbot’s accuracy. |
关键要点:每个LLM驱动的产品都需要一个定制的评估框架。这些标准应该既有用——专注于真正重要的事情——又有区别性,这意味着它们可以有效地突出迭代之间的性能差异。
为什么LLM评估很难
这些法学硕士评估远非直截了当。这不仅仅是因为质量标准是定制的:这种方法本身不同于传统的软件测试和预测性机器学习。
非确定性行为。
LLM产生概率输出,这意味着它们可能会对相同的输入产生不同的响应。

虽然这允许创造性和多样化的答案,但它使测试变得复杂:您必须检查一系列输出是否符合您的期望。
没有单一的正确答案。
传统的机器学习系统,如分类器或推荐器,处理预定义的输出。例如,一封电子邮件要么是垃圾邮件,要么不是,每个输入都有一个基本事实答案。为了测试模型,您可以创建一个具有已知标签的数据集,并检查模型预测标签的效果。
但LLM经常处理开放式任务,比如写电子邮件或在存在多个有效答案的情况下进行对话。例如,写一封好电子邮件有无数种方法。这意味着您不能依赖与参考答案的精确匹配。相反,你需要评估模糊的相似性或主观品质,如风格、语气和安全性。
多种可能的输入。
LLM产品通常处理不同的用例。例如,支持聊天机器人可能会回答有关产品、退货的查询,或帮助解决帐户故障。您需要基于场景的测试,以覆盖所有预期的输入。创建一个好的评估数据集是另一个需要解决的问题!
更重要的是,在测试中有效的方法并不总是适用于野外。现实世界的用户可能会向您的系统抛出意外的输入,使其超出您的计划。为了检测到这一点,您需要观察和评估在线质量的方法。
独特的风险。
使用经过训练以遵循自然语言指令的概率系统会带来新类型的漏洞,包括:
- 幻觉。该系统可能会产生虚假或误导性的事实,比如发明不存在的产品或给出不正确的建议。
- 越狱。恶意用户可能会试图绕过安全措施,引发有害或不恰当的反应。
- 数据泄露。LLM可能会无意中泄露其培训数据或连接系统中的敏感或私人信息。
您需要正确的评估工作流程来解决所有这些问题:对系统进行压力测试,发现其弱点,并监控其在野外的性能。你是怎么做到的?
让我们来看看可能的方法!
LLM评估方法
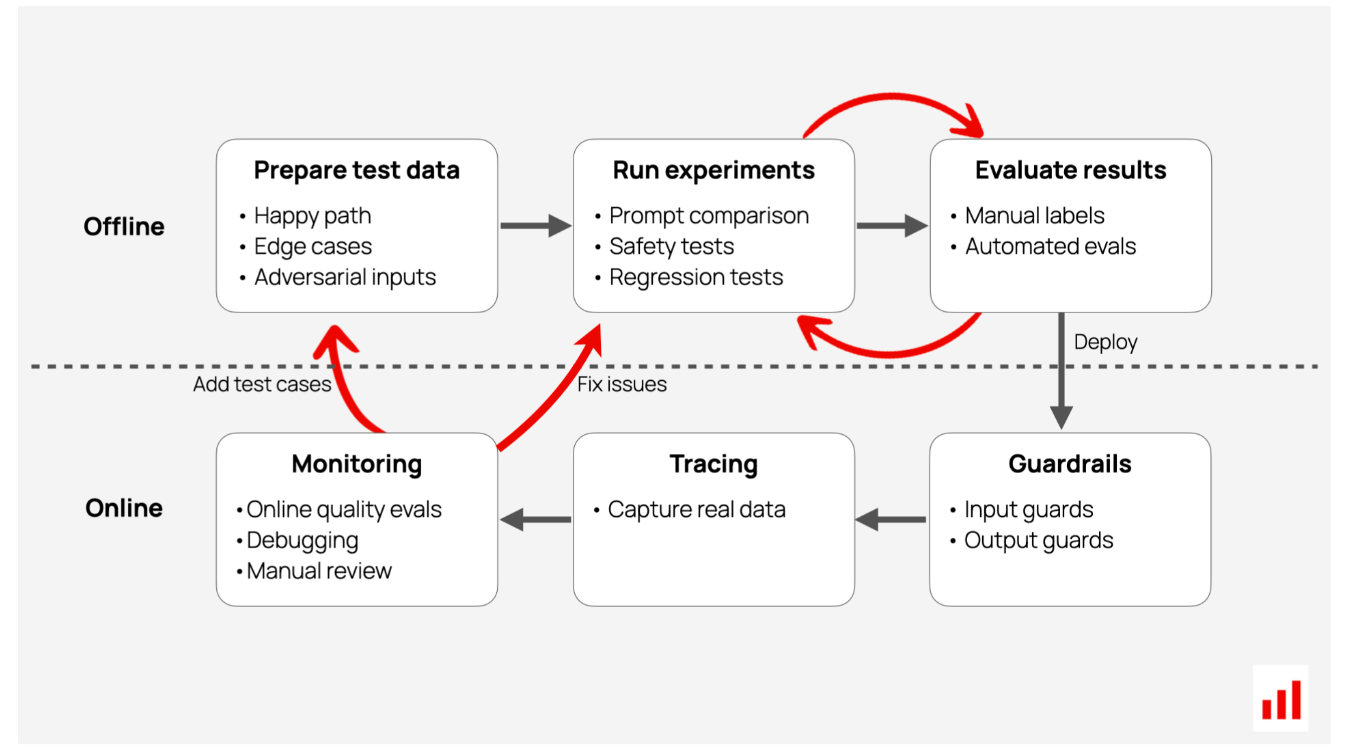
LLM评估通常发生在两个关键阶段:部署前和启动后。
在开发阶段,当你迭代构建应用程序时,你需要检查它是否足够好。一旦它上线,你就可以监控它是否运行良好。无论处于哪个阶段,每次评估都是从数据开始的。你首先需要一些东西来评估。
- 测试数据有助于您进行实验。这些是模拟LLM可能遇到的场景的示例输入。您可以手动编写测试用例、综合生成或从测试版用户那里获取。一旦你有了这些输入,你就可以测试你的LLM应用程序对它们的反应,并根据你的成功标准评估输出。
- 生产数据。一旦应用程序上线,就要看看它在真实用户中的表现。您需要捕获系统输入和响应,并对实时数据进行持续的质量评估,以发现任何问题。
在测试和生产中,您可以在手动和自动LLM评估之间进行选择。
手动LLM评估
最初,你可以通过问:“这些反应感觉对吗?”来进行简单的“氛围检查”
创建第一个提示版本或RAG设置后,您可以通过LLM应用程序运行一些示例输入,并查看响应。如果它们离得很远,你可以调整提示或调整你的方法。
即使在这个非正式阶段,你也需要测试用例。对于支持机器人,您可以准备一些已知答案的示例问题。每次你改变一些东西,你都会评估法学硕士对它们的处理程度。
虽然不是系统的,但氛围检查可以帮助你查看事情是否正常,发现问题,并提出新的即时想法。然而,这种方法既不可靠,也不可重复。随着你前进,你需要更多的结构——有一致的评分和详细的结果记录。
利用人类专业知识的一种更严格的方法是标签或注释过程:您可以创建一个正式的工作流程,让审阅者使用设定的指令来评估回复。 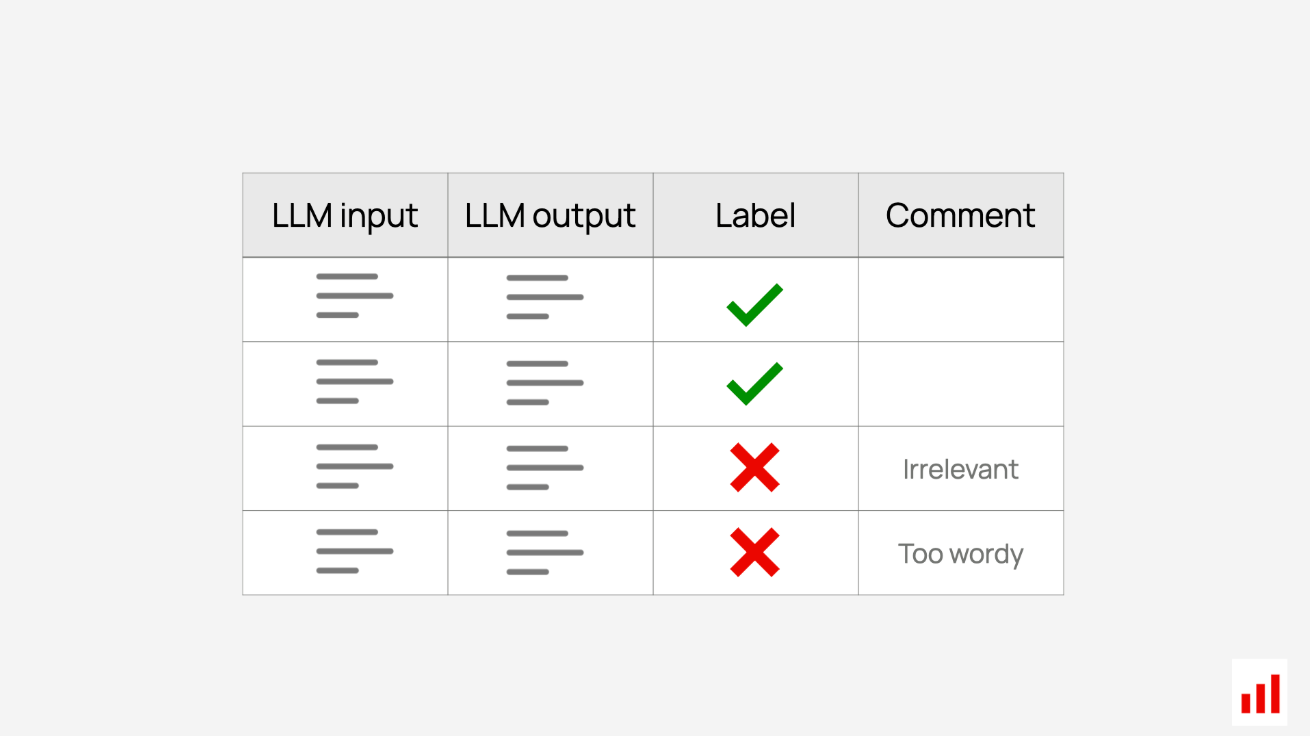
手动评估输出质量。
他们可以给出二进制标签,如“通过”或“失败”,或者评估特定的质量,如提取的上下文是否“相关”,或者答案是否“安全”。你也可以要求审阅者简要解释他们的决定。
为了使标签过程高效一致,您必须提供明确的说明,比如要求查找特定的错误类型。您还可以让多个审阅者评估相同的输入,以提出相互冲突的意见。
这些手动LLM评估是确定您的LLM应用程序是否工作良好的最可靠方法。作为产品构建者,您最有能力定义“成功”对您的用例意味着什么。在医疗保健等高度细致入微和专业化的领域,您可能需要聘请主题专家来帮助判断这一点。
示例:Asana分享了如何通过产品经理进行的自动化单元测试和手动评分来测试AI驱动的功能。这个动手过程帮助发现了许多质量和格式问题。
虽然非常有价值,但手动标签的获取成本很高。您不能每次编辑提示时都查看数千个输出。你需要自动化来扩展。
自动化LLM评估
通过一些前期工作,您可以自动化这些LLM评估。它们分为两类:
- 使用基本事实:将LLM的输出与目标参考答案进行比较。
- 没有事实依据:直接为答案分配定量分数或标签。
使用基本事实
这些LLM评估依赖于预定义的正确答案,通常称为“参考”、“基本事实”、“黄金”或“目标”答案。
例如,在客户支持系统中,“您的退货政策是什么?”的目标响应可能是“您可以在30天内退货。”您可以将聊天机器人的输出与这些已知答案进行比较,以评估响应的整体正确性。

基于参考的评估:将新结果与预期结果进行比较。
这些LLM评估本质上是离线的。您在迭代应用程序时或在将更改部署到生产环境之前运行测试。
要使用这种方法,您首先需要一个LLM评估数据集:一组样本输入及其批准的输出。您可以生成这样的数据集或从历史日志中整理它,就像使用人类支持代理的过去响应一样。这些案例越接近真实世界的情况,你的评估就越可靠。
示例:GitLab分享了他们如何构建Duo,这是他们的一套人工智能功能。他们创建了一个包含数千个基本事实答案的评估框架,并每天进行测试。它们还具有较小的代理数据集,用于快速迭代。
一旦你的数据集准备就绪,以下是自动化LLM评估的工作原理:
- 输入测试输入。
- 从您的系统生成响应。
- 将新答案与参考答案进行比较。
- 计算总体质量分数。
棘手的部分是将反应与实际情况进行比较。你如何判断新的答案是否正确?
精确匹配是一个显而易见的想法:看看新的响应是否与目标响应相同。

完全匹配:检查新响应是否与预期一致。
但精确的匹配往往过于僵化——在开放式场景中,不同的措辞可以传达相同的含义。为了解决这个问题,您可以使用其他方法,例如量化两个响应之间的单词重叠,使用嵌入比较语义含义,甚至要求LLM进行匹配。

语义匹配:检查新响应是否传达了相同的含义。
以下是常见匹配方法的快速分解:
| Method | Description | Example |
|---|---|---|
| Exact Match | Check if the response exactly matches the expected output (True/False). | Confirm a certain text is correctly classified as “spam”. |
| Word or Item Match | Check if the response includes specific words or items, regardless of full phrasing (True/False). | Verify that “Paris” appears in answers about France’s capital. |
| JSON match | Match key-value pairs in structured JSON outputs, ignoring order (True/False). | Verify that all ingredients extracted from a recipe match a known list. |
| Semantic Similarity | Measure similarity using embeddings to compare meanings. (E.g., cosine similarity). | Match “reject” and “decline” as similar responses. |
| N-gram overlap | Measure overlap between generated and reference text (E.g. BLEU, ROUGE, METEOR scores). | Compare word sequence overlap between two sets of translations or summaries. |
| LLM-as-a-judge | Prompt an LLM to evaluate correctness (Returns label or score). | Check that the response maintains a certain style and level of detail. |
在匹配了单个响应的正确性后,您可以在测试数据集上分析系统的整体性能。
对于二进制真/假匹配,准确度(正确响应的百分比)是一个直观的指标。对于语义相似性等数字分数,平均值很常见,但可能无法说明全部情况。相反,您可以查看低于设定相似性阈值的响应份额,或在所有示例中测试最低分数。
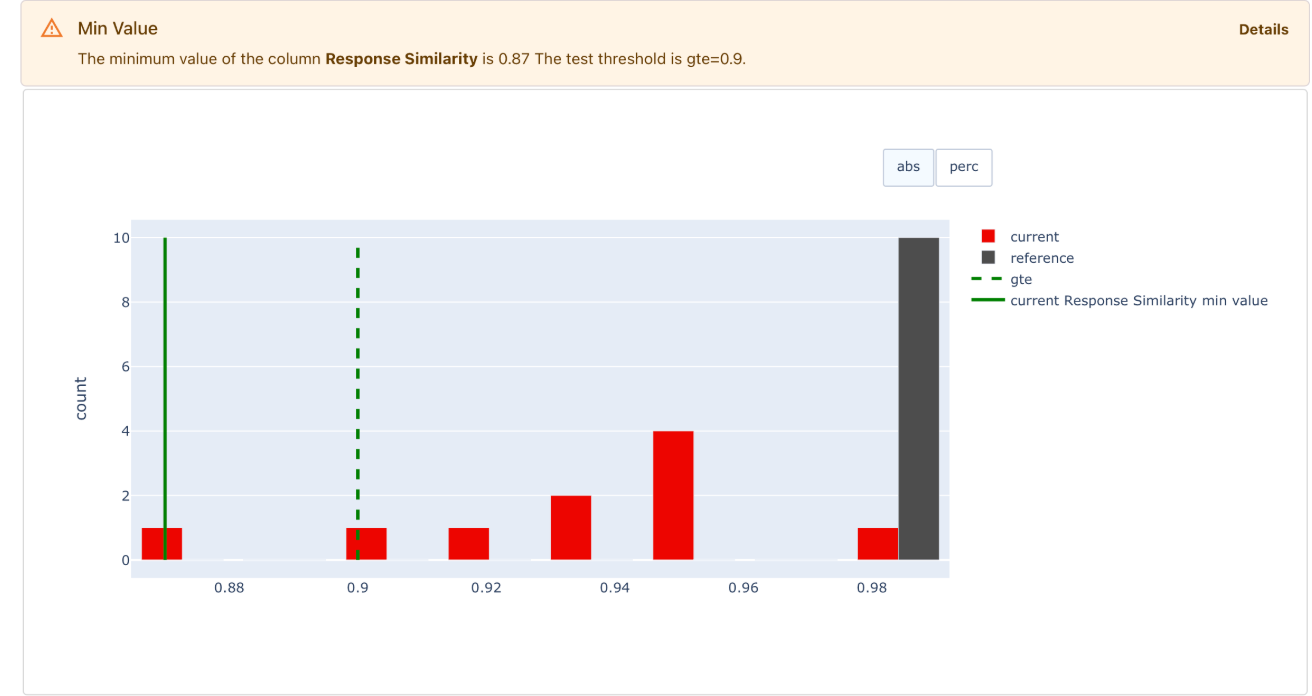
您可以运行测试,查看是否有任何相似性较低的响应。
如果你正在使用LLM进行预测任务,这通常是大型LLM解决方案的一个组成部分,你可以使用经典的ML质量指标。
| Task | Example metrics | Example use case |
|---|---|---|
| Classification | Accuracy, precision, recall, F1-score. | Spam detection: recall helps quantify whether all spam cases are caught. |
| Ranking | NDCG, Precision at K, Hit Rate, etc. | Retrieval in RAG: Hit Rate checks if at least one relevant result is retrieved for the query. |
将新响应与参考响应相匹配的原则是通用的,但细节因用例而异。以下是一些示例:
- 总结。通过将新的总结与参考的人工编写示例进行比较来评估它们。使用基于嵌入的语义相似性、LLM判断相似性或单词重叠等方法。
- 结构化信息提取。对于从笔记中提取信息等任务,请将系统生成的JSON输出和参考JSON进行比较。这可以通过编程来实现。
- 检索。使用排名指标将给定查询的检索文档与包含正确答案的一组已知文档进行比较。
设置好数据集和评估器后,您可以在需要时运行评估。例如,在调整提示后重新运行测试,看看情况是好转还是恶化。
没有事实依据

无参考文献评估:根据所选标准直接对回复进行评分。
然而,获得事实真相的答案并不总是可行的。对于复杂的开放式任务或多回合聊天,很难定义一个“正确”的回应。在生产中,没有完美的参考:你正在评估产出。
您可以运行无参考的LLM评估,而不是将输出与固定答案进行比较。他们评估输出的具体质量,如结构、语气或意义。
一种流行的LLM评估方法是使用LLM作为评判,在这种方法中,您使用语言模型根据一组量规对输出进行评分。例如,LLM法官可能会评估聊天机器人的响应是否完全回答了问题,或者输出是否保持了一致的语气。
但这不是唯一的选择。以下是一个快速概述:
| Method | Description | Example |
|---|---|---|
| LLM-as-a-Judge | Use an LLM with an evaluation prompt to assess custom properties. | Check if the response fully answers the question fully and does not contradict retrieved context. |
| ML models | Use specialized ML models to score input/output texts. | Verify that text is non-toxic and has a neutral or positive sentiment. |
| Semantic similarity | Measure text similarity using embeddings. | Track how similar the response is to the question as a proxy for relevance. |
| Regular expressions | Check for specific words, phrases, or patterns. | Monitor for mentions of competitor names or banned terms. |
| Format match | Validate structured formats like JSON, SQL, and XML. | Confirm the output is valid JSON and includes all required keys. |
| Text statistics | Measure properties like word count or symbols. | Ensure all generated summaries are single sentences. |
这些无参考的LLM评估既可以在迭代开发过程中(比如当你优化音调或格式的输出时)也可以用于监控生产性能。
虽然在这种情况下你不需要设计和标记地面实况数据集,但你仍然需要做一些前期工作。这一次,你的重点是:
策划一组多样化的测试输入
对评估人员进行微调。
缩小和表达评估标准需要一些思考。一旦你设定了这些标准,你可能需要与LLM法官等评估人员合作,以符合你的期望。
LLM评估场景
总之,所有LLM评估都遵循相同的结构。
您从一个评估数据集开始,其中包括测试或生产数据。对于测试,它也可能包含地面真相。
您决定LLM评估方法:手动审查或自动评分。
您根据特定标准评估输出,无论是相对于参考响应的正确性,还是音调和结构等质量。
您可以结合手动和自动方法。
示例:Webflow有效地使用了这种混合方法。他们依靠自动评分进行日常LLM验证,并每周进行人工审查。
虽然所有LLM评估都依赖于相同的元素(数据、标准、评分方法),但您出于不同的原因运行它们。以下是LLM产品生命周期中的常见场景。
LLM评估比较
为您的AI产品选择最佳型号、提示或配置。
开始时,你的第一步通常是进行比较。
您可以从选择模型开始。你查看排行榜,挑选一些候选LLM,并在你的任务中测试它们。例如,OpenAI模型是否优于Anthropic的模型?或者,如果你转向更便宜或开源的模式,你会损失多少质量?
另一个比较任务是找到最佳提示。
假设你正在构建一个总结工具。“用简单的术语解释”会比“编写TLDR”更好吗?如果你将任务分解为步骤或使用一系列提示怎么办?或者可以添加所需风格的示例?这个过程被称为快速工程,需要一些尝试和错误。小的调整往往会产生很大的影响,因此在数据集上系统地测试每个版本是关键。
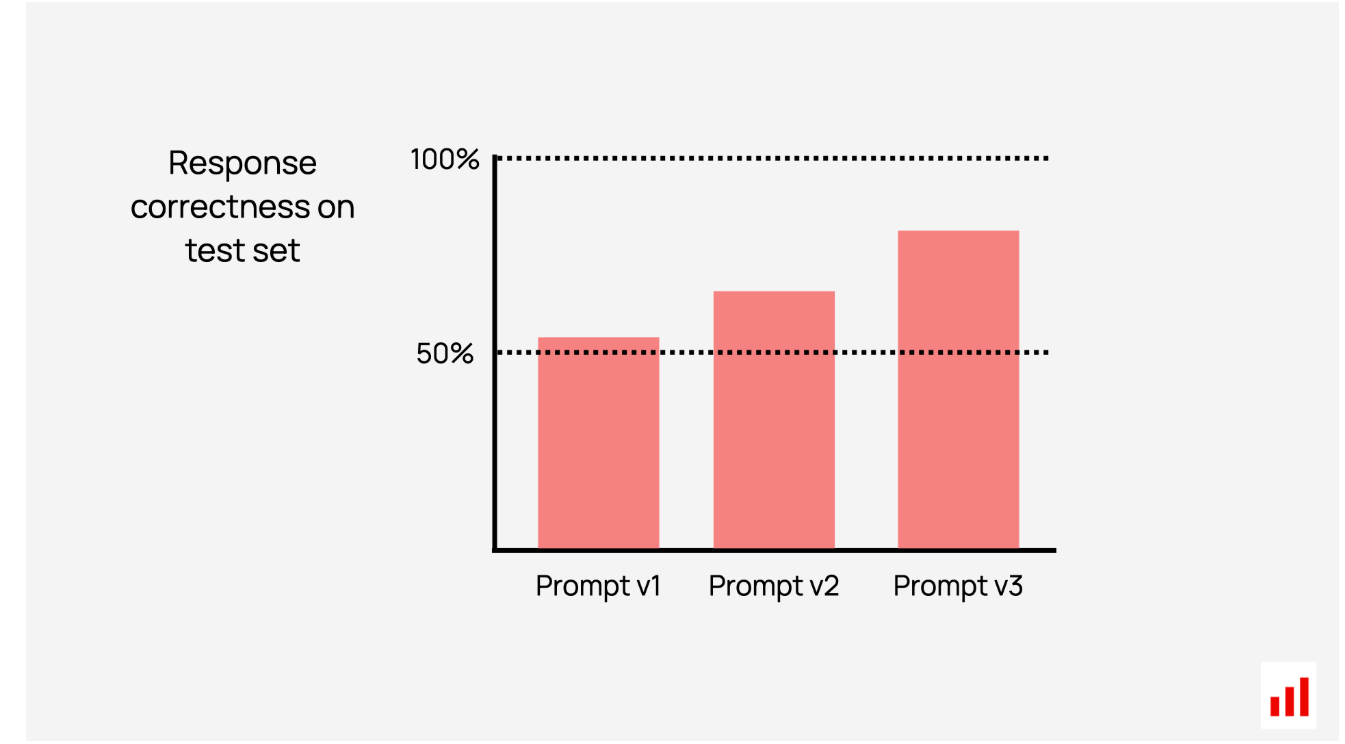
比较评估有助于你看到你随着时间的推移而取得的进步。
根据用例的不同,您还可以尝试RAG的分块策略、温度设置或不同的检索方法。
每一个变化都是一个新的实验,你需要LLM评估来比较他们的结果。这意味着要有精心策划的测试数据集和自动化的方法来衡量性能。您可以使用基本事实方法(如与理想摘要进行比较)和无参考方法(如检查所有生成的摘要是否遵循既定结构,保持正确的语气,并且不与来源相矛盾)。
您还可以尝试使用LLM判断进行成对比较——显示两个输出,并要求模型选择更好的输出。要做到这一点,你需要投资校准你的eval提示,并注意偏见,比如倾向于先出现或最后出现的输出。
为了有效地进行实验,建立基线是有用的。在更复杂的设置之前尝试简单的方法——这为您提供了一个衡量进度的明确基准。
在迭代时搁置一些测试用例也是一个明智之举。在机器学习中,这被称为保留数据集。没有它,你就有过度拟合的风险,即应用程序在测试示例上表现良好,但在处理新的、看不见的数据时遇到困难。为了避免这种情况,请将部分示例分开,只有在您对初始结果感到满意时才能对其进行测试。
虽然实验的细节可能会发生变化,但目标保持不变:找出最有效的方法并交付一个伟大的产品。一个可靠的评估系统有助于更快地做出数据驱动的决策。例如,您可以量化它在测试数据集上的表现,而不是仅仅说一个提示似乎更好。
LLM压力测试
通过在各种场景(包括边缘案例)中评估LLM产品,检查其是否已准备好用于现实世界。
当你运行实验时,你自然会想要扩大你的测试覆盖率。您最初的示例集可能很小。但是,一旦你选择了一个模型,解决了输出格式等基本问题,并确定了提示策略,是时候进行更彻底的测试了。你的系统可能在十几个输入上运行良好,但几百个呢?
这意味着要添加更多的示例,以涵盖更常见的用例,并了解系统如何处理更棘手的场景。
例如,在支持问答系统中,您可以从简单的查询开始,如“您的退货政策是什么?”然后,您可以扩展到其他主题,如账单,并添加更复杂的问题,如“为什么我被收取了两次费用?”或“我可以换掉去年购买的商品吗?”
您还可以测试稳健性,并对同一问题的多个回答进行抽样,以了解它们的变化程度。
下一步是研究边缘情况——需要特殊处理的现实但棘手的场景。比如,如果输入是一个单词,会发生什么?或者如果它太长了?如果它是另一种语言或充满拼写错误怎么办?该系统如何处理它不应该处理的敏感话题,比如关于竞争对手的问题?

设计这些需要一些思考。您必须了解用户如何与您的产品交互,以创建逼真的测试用例。合成数据在这里非常有用——它可以让你快速创建常见问题的变体,或者想出更多不寻常的例子。
最终,您希望为每个主题或场景提供一组LLM评估数据集,并配以测试它们的方法,例如匹配的预期答案或自动评估的可衡量标准。
例如,如果你希望你的系统拒绝竞争对手的问题,你可以:
- 创建一个包含竞争对手相关问题的测试数据集。
- 为这些输入生成响应。
- 检查所有响应是否正确拒绝了请求。
为了验证LLM是否正确拒绝回答,您可以查找特定单词的存在,检查与已知否认的语义相似性,或使用LLM判断。
从技术上讲,压力测试与实验性LLM评估没有太大区别。区别在于重点:你不是在探索选项(比如哪个提示最有效),而是在检查产品是否已准备好投入实际使用。问题转移到,我们的产品以其目前的提示和设计,能处理用户扔给它的一切吗?
理想情况下,您应该使用现有的LLM设置(不对提示或架构进行更改),并通过这些额外的场景运行它,以确认它对所有挑战都做出了正确的响应。检查!
但实际上,你可能会发现问题。一旦你解决了这些问题,你就可以重新运行LLM评估,以确保它们得到解决。修复可能涉及改进提示、调整系统的非LLM逻辑或添加保护措施,如阻止特定类型的请求。
也就是说,还有一件事需要测试:对抗性输入。
LLM红队
测试您的系统如何应对对抗行为或恶意使用。
LLM红队是一种测试技术,您可以模拟即时注入或馈送对抗输入等攻击,以发现系统中的漏洞。这是评估高风险应用的人工智能系统安全性的关键一步。
虽然压力测试侧重于具有挑战性但合理的场景,比如普通用户可能会问的复杂查询,但红队的目标是滥用。它寻找不良行为者可能利用该系统的方式,将其推向不安全或意外的行为,比如给出有害的建议。
边缘情况和对抗性输入之间的界限有时可能很窄。例如,医疗保健聊天机器人必须安全地处理医疗问题,作为其核心功能的一部分。测试这属于其正常范围。但对于一般支持问答系统,医疗、财务或法律问题超出了其预期用途,被视为对抗性问题。
法学硕士红队还可以测试产生露骨或暴力内容、宣传仇恨言论、允许非法活动、侵犯隐私或显示偏见等风险。
这可能涉及动手测试和更具可扩展性的方法。例如,你可以手动尝试欺骗人工智能系统同意有害的请求或泄露敏感信息。为了扩大流程规模,您可以运行自动化的LLM红队,使用合成数据和有针对性的提示等技术来模拟各种风险。
例如,为了测试偏见,您可以:
- 使用合成数据或道德基准创建对抗性输入,以引发敏感或不恰当的反应。
- 在系统中运行这些输入。
- 检查所有输出是否拒绝不安全的请求或避免有问题的语句。
与其他LLM评估一样,红队可以根据应用程序的具体情况进行定制。
测试通用的有害行为(比如问直截了当或挑衅性的问题)很重要,但针对特定情境的测试可能更有价值。例如,你可以检查当你改变问同一问题的人的年龄或性别时,应用程序是否会给出不同的建议。
LLM可观测性
了解系统的实时性能,以检测和解决问题。
离线LLM评估只能带你走这么远。在某个时候,你会把你的产品放在真实用户面前,看看它在野外的表现。如果你的用例不涉及重大风险,你可能会提前启动测试版,开始收集现实世界的反馈。
这就引出了下一个评估场景:生产LLM可观察性。
一旦你的产品上线,你就要跟踪它的性能。用户是否有良好的体验?答案是否准确、安全和有用?
你可以从跟踪用户行为开始,比如捕捉点击或参与信号,或者收集明确的用户反馈,比如要求用户对响应投赞成票或反对票。然而,这些产品指标只能给你提供顶层的见解(用户似乎喜欢它吗?),但它们并没有揭示交互的实际内容,也没有揭示事情的正确或错误之处。
为了获得更深入的见解,您需要跟踪用户的问题以及您的系统如何响应。这始于收集痕迹:所有交互的详细记录。
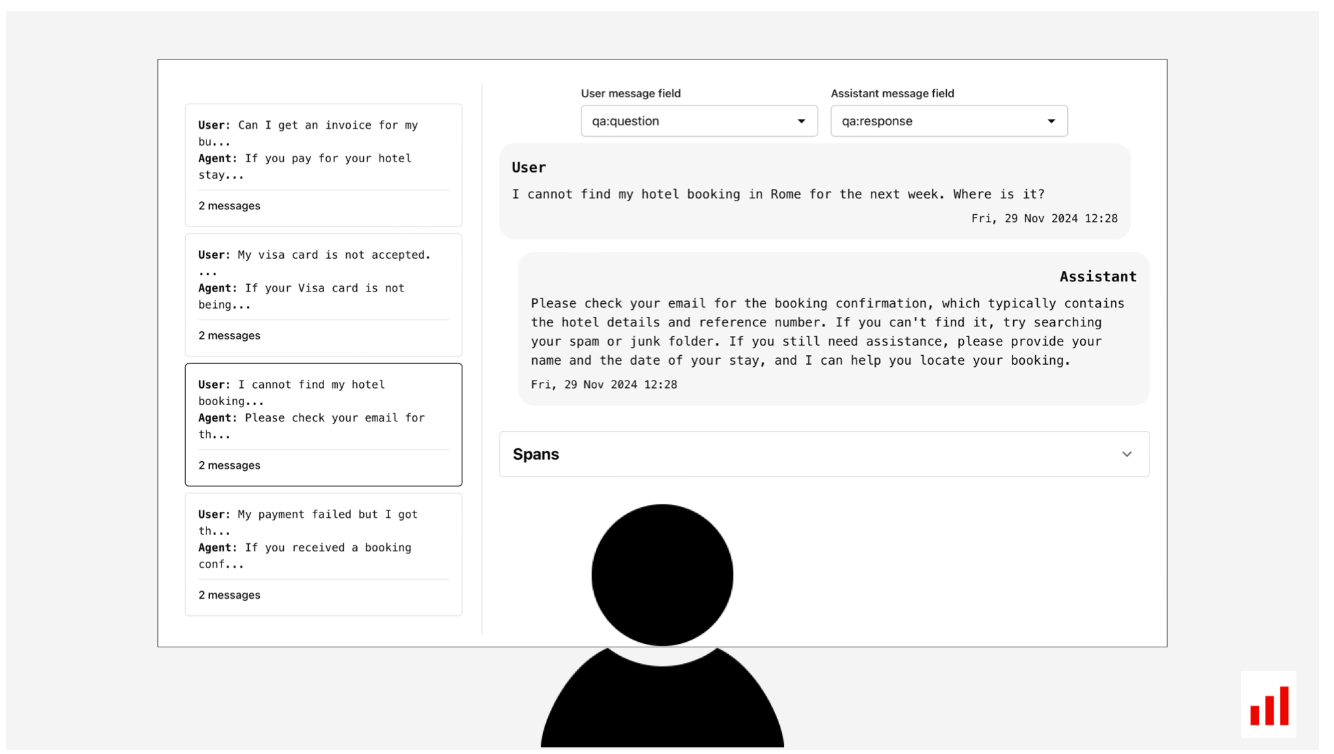
拥有这些痕迹将使您能够通过运行在线LLM评估来评估生产质量。您可以使用LLM判断、ML模型或正则表达式等无引用方法自动处理每个新输出(或部分输出),以查看它们在您的标准下的得分情况。
在线LLM可观察性也有助于您更多地了解您的用户。哪些请求最受欢迎?哪些是出乎意料的?它类似于产品分析,但侧重于分析文本交互。例如,您可以对用户请求进行聚类,以发现常见主题并决定优先考虑哪些改进。
您还可以通过A/B测试来测试更改。例如,您可能会向10%的用户部署一个新的提示,并比较性能指标,看看它是否提高了质量。
如果出现问题——比如负面反馈激增或情绪评分下降——你可以深入日志进行故障排除。这意味着要审查具体的互动,以确定出了什么问题。您的LLM可观察性设置应该使分析单个响应以进行调试变得容易。
人工审查仍然非常有价值。虽然你不能在生产中检查每一个响应,但定期检查较小的样本——无论是随机样本还是自动检查标记的样本——都是非常有用的。它可以帮助您建立对工作原理的直觉,策划新的测试用例,并随着产品的发展完善您的评估标准。
LLM回归测试
测试新的更改是否在不破坏以前工作的情况下改进了系统。
即使你的产品已经上线,你也需要离线评估来运行LLM回归测试。它们允许您验证所做的更改不会引入新的(或旧的)问题。
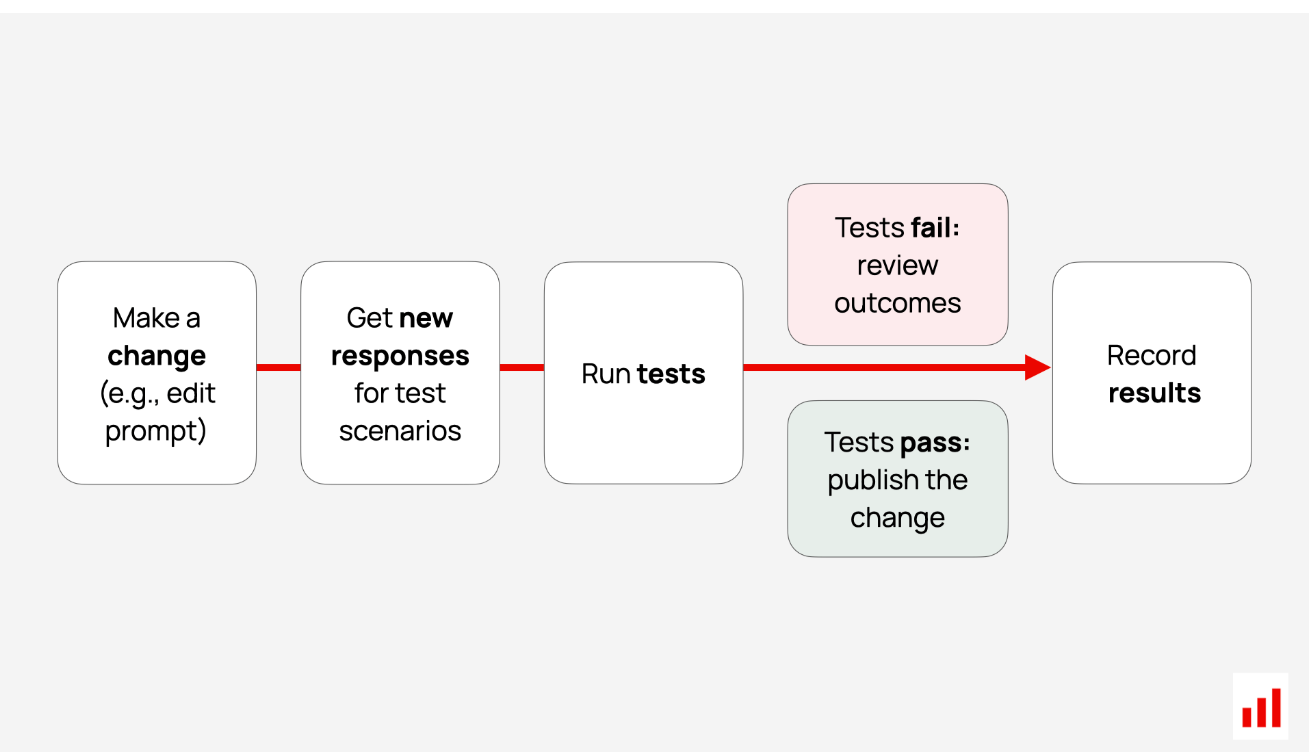
质量迭代很少停止。当你了解更多关于用户如何与你的应用程序交互或发现特定故障的信息时,你自然会想要进行更新——比如调整提示。但每一个变化都伴随着风险:如果修复一件事会破坏另一件事怎么办?
例如,如果你稍微调整一个提示,之前的输出会改变多少?这些变化实际上是更好还是更坏?为了保持领先地位,您需要一种通过重新运行测试用例来批量测试更新的方法,以确认:
- 在仍然工作之前纠正输出。
- 您的更改解决了您所针对的问题或提高了整体质量。
如果测试通过,您可以安全地将更新发布到生产环境。
您的测试数据集也必须不断发展,以反映实际的用户行为。好消息是,您可以直接从日志中提取新的示例并将其转换为测试用例。
对于较大的更新,您可以将所有最近的生产数据视为测试集。例如,获取上周的所有输入和输出,将其推送到新的LLM应用程序版本中,重新生成响应,并检查哪些响应发生了变化以及如何变化。这有助于您发现任何意外的副作用。

系统的LLM回归测试可帮助您在现有系统的基础上安全构建。您可以进行更改,同时确保在此过程中不会产生新的问题。
LLM护栏
实时检查,检测LLM输入或输出中的质量问题。
有时,你想立即发现问题。与评估过去或测试交互不同,这意味着实时检测有问题的输入或输出。这些验证被称为护栏,充当系统响应和用户之间的安全网。
在内部,这些检查是相同的无参考LLM评估,但直接内置到您的应用程序中并实时应用。例如,您可以查看:
- 输入:检测有问题的查询,比如关于禁止主题或包含有毒语言的问题。
- 输出:检测回复是否包含个人身份信息(PII)或类似法律建议。
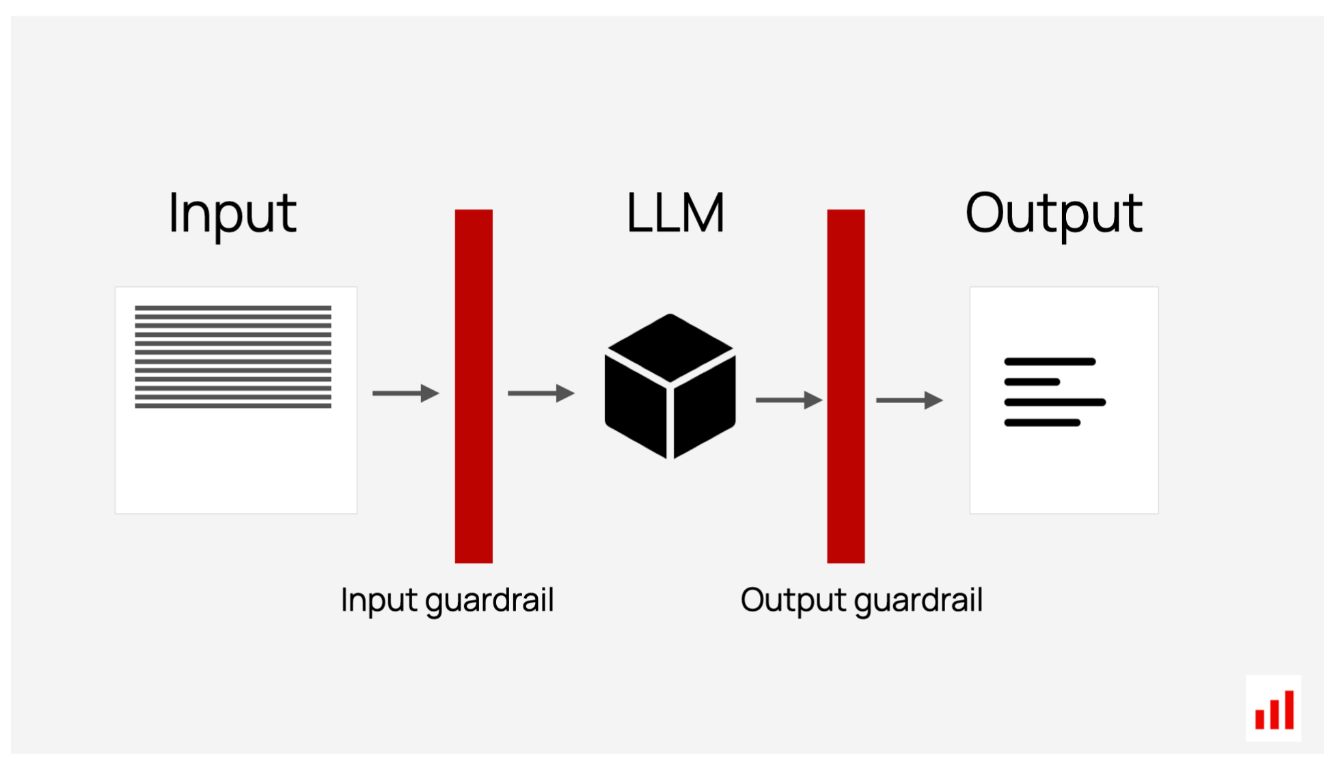
您可以在检测到问题时定义适当的操作。系统可能会简单地阻止响应并显示一条回退消息,如“很抱歉,我帮不了你。”或者,它可以应用缓解措施,例如删除私人数据或不恰当的语言,或者用不同的提示重试响应。
虽然LLM护栏很有价值,但它们也有权衡。额外的处理可能会引入延迟。一些检查,比如识别特定单词的正则表达式,速度很快。但是,更复杂的检查,比如那些调用其他LLM的检查,可能需要更长的时间,并会减慢应用程序的响应速度。它们也可能不适用于流式输出,在流式输出中,响应在生成时实时显示给用户。
由于这些限制,护栏通常是为最关键的风险保留的,例如阻止有毒物质或识别个人身份信息。使用时,它们充当实时、自动化的评估,以确保您的系统安全和合规。
回顾

- 好消息:人工智能还没有接管一切。即使是基于LLM的产品,你仍然需要人为投入来管理质量。如果不实际审查所有输出,那么就设计和维护自动化的LLM评估系统。
- 坏消息:LLM评估并不简单。每个应用程序都需要基于其用例、风险和潜在故障模式的自定义方法。例如,与用户可以干预的内部工具相比,面向消费者的聊天机器人在安全性和准确性方面的风险要高得多。
从第一个产品提示到生产的每个阶段都需要LLM评估。这些工作流程并不是孤立的——每一步都建立在前一步的基础上:
你经常从比较实验开始,看看什么最有效。这里的一个关键先决条件是一个好的测试数据集。你需要投入时间来策划一个,并在收集新的见解时不断更新。
在发布之前,您可以进行压力测试和红队合作,为棘手的情况做好准备。
当你的应用程序上线时,护栏可以帮助发现和预防重大问题。
一旦你的产品问世,人工智能驱动的系统就需要持续监控。这不是一个“设置后就忘记”的交易。您需要生产可观察性,以便通过在线评估了解系统处理实时数据的能力。
如果出现问题,您可以修复它,运行回归测试,并推出更新。
自动和手动LLM评估齐头并进。虽然人类标签可以给出最清晰的信号,但自动评估有助于复制和扩展这些见解。
所有这些法学硕士评估不仅仅是为了处理指标。他们帮助您:
打造更好的AI产品。它们有助于为现实世界的用户创建可靠的应用程序。
防止故障。您可以及早发现问题,从边缘情况到生产错误。
移动得更快。没有评估,改变是缓慢而危险的——你不知道你破坏了什么或修复了什么。自动LLm评估有助于运行更多的实验并更快地发布更新,无论是修复错误还是切换到新的、更具成本效益的LLm。
一个可靠的LLM评估过程还有另一个好处:它自然会收集高质量的标记数据。稍后,您可以使用它来优化您的系统——用较小的模型替换LLM判断,优化生产提示,甚至微调您的主模型。
开始LLM评估
LLM评估可能很复杂,特别是对于RAG、AI代理和关键任务应用程序等高级系统。这就是为什么我们构建了Evidently,一个下载量超过2500万的开源框架。它简化了评估工作流程,提供100多个内置检查,并可轻松配置自定义LLM法官以满足您的需求。
对于团队来说,Evidently Cloud提供了一个协作的、无代码的平台来测试和评估人工智能的质量。您可以生成合成数据来运行场景测试和AI代理模拟,管理数据集,跟踪交互,并直接从界面运行评估。

- 登录 发表评论
- 57 次浏览